
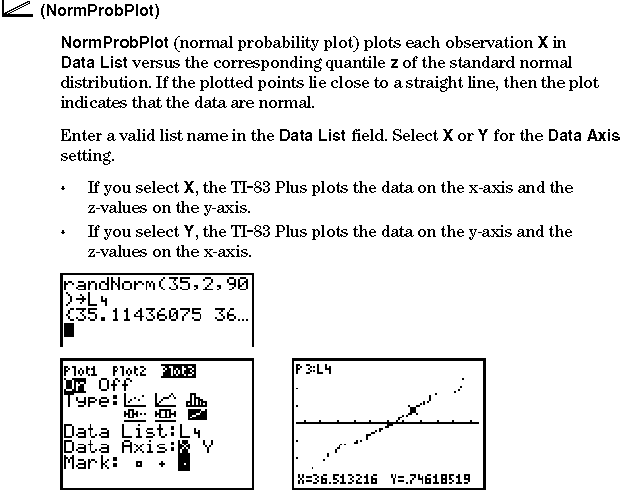
Bild 1: Aufruf des STAT - Menüs zur Dateneingabe in List 1 |

Bild 2: Dateneingabe im List 1 - Arbeitsfenster, List 1 muß eine Urliste (mit allen Datenwiederholungen) sein. |

Bild 3: Aufruf eines weiteren Untermenüs für das SET UP Einstellung auf automatische Fensteranpassung für die statistische Grafik mit Stat Wind :Auto |
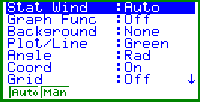
Bild 4: Weitere Einstellungen im SET UP speziell muß Coord :On eingestellt sein, um später über die Trace-Taste Punktkoordinaten abfragen zu können. |
Bild 5: Einstellungen für die statistische Grafik StatGraph1 |
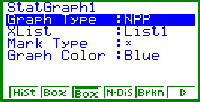
Bild 6: Aktivierung der statistischen Grafik StatGraph1 :On |
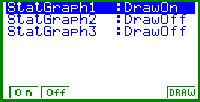
Bild 7: Das View Window mit Zoom - Auto ist optimal (Xscale und Yscale muß per Hand eingetragen werden.) |
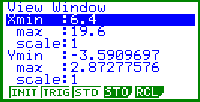
Bild 8: Umstellung des Automatic-Zoom auf Stat Wind :Manual, falls der Fensterausschnitt später per Hand eingestellt werden soll. |
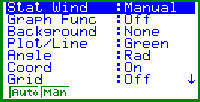
Bild 9: Das View Window nach der Einstellung per Hand |

Wir betrachten dazu den Datensatz (Urliste mit n = 60) aus Beispiel 17.1 im Lehr- und Übungsbuch Mathematik, Band 3: Lineare Algebra - Stochastik, S. 232, (von Aulenbacher,G., Paditz,L., Wabel-Frenk,U. (Hrg. v. Prof. Dr .W.Preuß, HTW Dresden, u. Prof. Dr. G.Wenisch, FH Darmstadt), 2. Aufl., Fachbuchverlag Leipzig im Hanser Verl. München, 2.Aufl. 2001):
16 |
15 |
17 |
16 |
19 |
17 |
16 |
16 |
16 |
18 |
15 |
14 |
14 |
14 |
15 |
11 |
7 |
8 |
10 |
9 |
11 |
11 |
13 |
12 |
12 |
12 |
14 |
13 |
13 |
15 |
11 |
9 |
12 |
10 |
12 |
11 |
12 |
14 |
13 |
11 |
12 |
14 |
15 |
13 |
14 |
15 |
18 |
16 |
17 |
16 |
15 |
14 |
13 |
14 |
14 |
12 |
14 |
12 |
13 |
12 |
Die primäre Häufigkeitstabelle hat folgende Gestalt:
Index |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
xi |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
hi |
1 |
1 |
2 |
2 |
6 |
10 |
7 |
11 |
7 |
7 |
3 |
2 |
1 |
hi / n |
1/60 |
1/60 |
2/60 |
2/60 |
6/60 |
10/60 |
7/60 |
11/60 |
7/60 |
7/60 |
3/60 |
2/60 |
1/60 |
sum hi / n |
1/60 |
2/60 |
4/60 |
6/60 |
12/60 |
22/60 |
29/60 |
40/60 |
47/60 |
54/60 |
57/60 |
59/60 |
60/60 |
sum [%] |
1,67 |
3,33 |
6,67 |
10,0 |
20,0 |
36,67 |
48,33 |
66,67 |
78,33 |
90,0 |
95,0 |
98,33 |
100,0 |
Die empirische Verteilungsfunktion y = wn(x) wird dem Lehr- und Übungsbuch Mathematik, Band 3: Lineare Algebra - Stochastik entnommen, vgl. S. 238, Formel (17.15) und Bild 17.2,
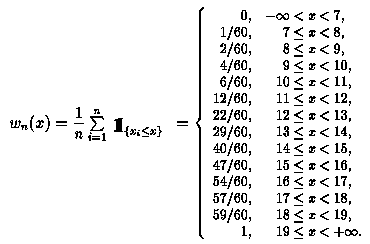
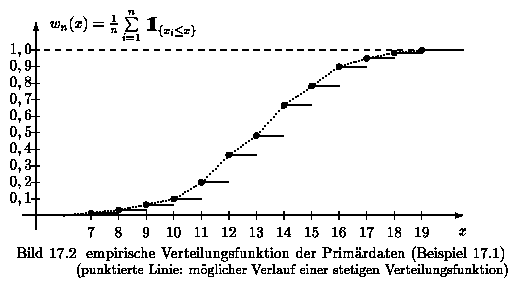
Es folgen nun zwei Darstellungen der empirischen Verteilungsfunktion im Wahrscheinlichkeitspapier:
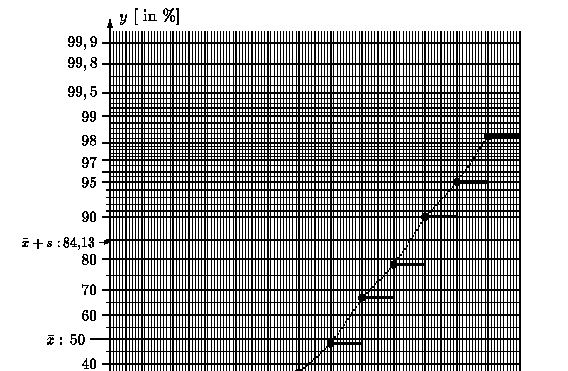
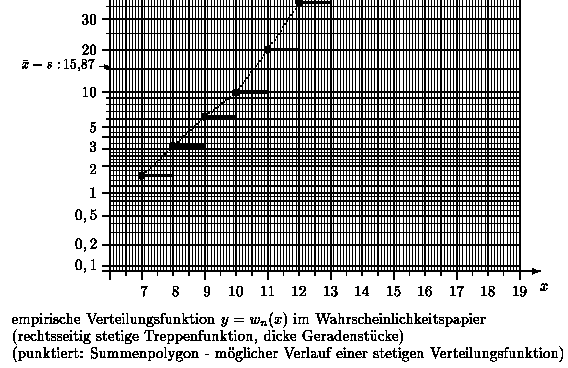

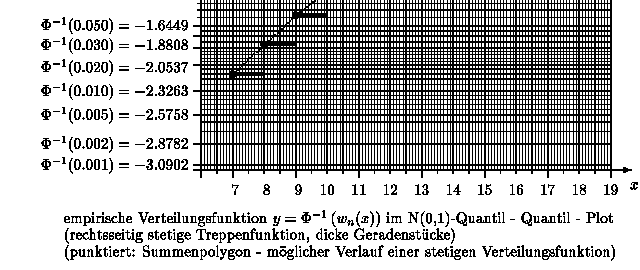
Durch den Übergang vom Wahrscheinlichkeitsniveau gamma zu den entsprechenden Quantilen y = zgamma = Phi-1( gamma) einer Normalverteilung wird die verzerrte Skalierung der y-Achse aufgehoben:
Die x- und y-Achse sind beide ohne Verzerrung skaliert. Die x-Achse enthält die "Quantile" der Urdaten (Variationsreihe) - also die Urdaten selbst. Die y-Achse enthält die "Quantile" einer Normalverteilung. Besitzt die so dargestellte Punktwolke ( x*k , yk ) , k = 1, 2, ..., n-1 , mit x*k = k-te Wert in der Variationsreihe und yk = Phi-1( k / n ) einen linearen Trend, so kann man vermuten, daß die Datenerhebung aus einer normalverteilten Grundgesamtheit herrührte.
Verschiedene statistische Grafiken vom Typ NPP mit Anzeige einzelner Koordinaten zu Punkten in der Punktwolke im Vergleich zur Darstellung im Wahrscheinlichkeitspapier:
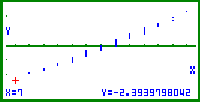
| Bild 10: Der größte Wert der Stichprobe x = 19 ( n-te Wert in der Variationsreihe, s. Cursor) erhält nicht wie üblich das Wahrscheinlichkeitsniveau 100% (dann wäre dieser Punkt genau wie im Wahrscheinlichkeitspapier nicht mehr darstellbar), sondern das um ( 1 / 2n ) * 100% reduzierte Wahrscheinlichkeitsniveau (( 2n - 1) / 2n ) * 100% = 98,33% und damit den y-Wert InvN(119/120) = Phi-1(0,9833) = 2.3939... usw. |
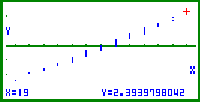
| Bild 11: Der vierte Wert x = 9 in der Variationsreihe der Stichprobe (s. Cursor) erhält nicht wie üblich das Wahrscheinlichkeitsniveau ( 4 / n ) * 100% = 6,667% , sondern das um ( 1 / 2n ) * 100% reduzierte Wahrscheinlichkeitsniveau ( 7 / 2n ) * 100% = 5,833% und damit den y-Wert InvN(7/120) = Phi-1(0,05833) = -1,5689... |
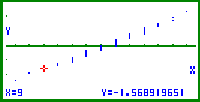
| Bild 12: Der dritte Wert x = 9 in der Variationsreihe der Stichprobe (s. Cursor) erhält nicht wie üblich das Wahrscheinlichkeitsniveau ( 3 / n ) * 100% = 5,000% , sondern das um ( 1 / 2n ) * 100% reduzierte Wahrscheinlichkeitsniveau ( 5 / 2n ) * 100% = 4,167% und damit den y-Wert InvN(5/120) = Phi-1(0,04167) = -1,7316... |
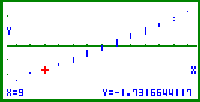
| Bild 13: Der kleinste Wert der Stichprobe x = 7 (s. Cursor) erhält nicht wie üblich das Wahrscheinlichkeitsniveau ( 1 / n ) * 100% = 1,67% (dann würde dieser Punkt genau wie im Wahrscheinlichkeitspapier dargestellt), sondern das um ( 1 / 2n ) * 100% reduzierte Wahrscheinlichkeitsniveau ( 1 / 2n ) * 100% = 0,833% und damit den y-Wert InvN(1/120) = Phi-1(0,0833) = -2.3939... |
| Bild 14: Notwendige Voreinstellung in View Window zur Darstellung eines Bildausschnittes |

| Bild 15: Bildausschnitt aus der statistischen Grafik NPP: deutlich sichtbar werden die senkrecht übereinanderliegenden Punkte bei Datenhäufung in einem bestimmten x-Wert Der Cursor zeigt hier bei x*30 = 14 auf den untersten Punkt bei y = InvN((2*30-1)/120) = -0,02089... |
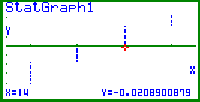
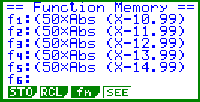
| Bild 16: Programmierung der empirischen Verteilungsfunktion y = wn(x) (Treppenfunktion) mit Hilfe von Rechteckimpulsen f1 bis f5, s. Bild 17. hier Eingabe von f1 im RUN-Modus: f1 = ( 50 * | x-10.99 | - 50 * | x-11 | - 50 * | x-12 | + 50 * | x-12.01 | ) (für Rechteckimpuls der Höhe 1 über 11 < x < 12 ) usw. |

| Bild 17: Darstellung der Rechteckimpulse f1 bis f5 im Function Memory zum weiteren Abruf im Y = - Fenster, vgl. Bild 18. |
| Bild 18: Skalierung der Rechteckimpulse auf die erforderlichen Höhen im NormProbPlot: z.B. Y1 = -0,8416 * f1 = InvN(12/60) * f1 usw. |
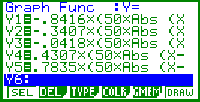
| Bild 19: Bildfenster der Funktions-Grafik: Darstellung der empirischen Verteilungsfunktion (Treppenfunktion) aus dem Wahrscheinlichkeitspapier durch Überlagerung der Rechteckimpulse Y1 bis Y5 (Abspeicherung als Background - Picture für die statistische Grafik NPP) |
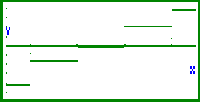
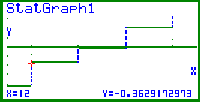
| Bild 20: Bildfenster der statistischen Grafik NPP: Überlagerung des NormProbPlots und der empirischen Verteilungsfunktion (Treppenfunktion) aus dem Wahrscheinlichkeitspapier. (Im SET UP für StatGraph1 wurde die Treppenfunktion als Background deklariert, da sich unterschiedliche Grafik-Typen (Funktionsgrafik und statistische Grafik) nicht gleichzeitig zeichnen lassen.) Der Cursor steht auf dem Wert x*22 =12 mit dem Quantil-Niveau 43/120 und InvN( 43 / 120 ) = -0,3629... < InvN( 22 / 60 ) = -0,34069... ( InvN( 22 / 60 ) als Wert der Treppenfunktion für 12 < x < 13 ), d.h. die Punktwolke im NormProbPlot ist um das Niveau 1 / n = 1 / 120 nach unten verschoben. |
Bemerkung: Der grüne Rahmen wurde nachträglich um die Bilder gezeichnet.
Hinweis: Link zum NormProbPlot mit dem TI-83 oder mit dem EL-9600,
wobei sowohl beim TI-83 (s. dort Bild 9 und Bild 10: bedingte Funktionswertbefehle im Y = - Menü möglich!)
als auch beim EL-9600 (s. dort Bild 13 u. 14: Line-Befehle im Draw-Menü!)
unterschiedliche Programmierungsmöglichkeiten für die Treppenfunktion genutzt wurden, die teilweise nur auf dem speziellen Taschenrechnermodell programmierbar sind.
Allgemein gilt damit für die Darstellung im CFX-9850G PLUS / CFX-9970G folgender Zusammenhang:
Dem k-ten x-Wert in der Variationsreihe wird das (kumulierte) Wahrscheinlichkeitsniveau (( 2k -1 ) / 2n ) * 100% und damit das N(0,1)-Quantil InvNorm( ( 2k -1 ) / 2n ) = Phi-1( ( 2k -1 ) / 2n ) = z( 2k -1 ) / 2n zugeordnet. Damit liegt die Punktwolke im NormProbPlot etwas tiefer als im Wahrscheinlichkeitspapier. Der gewünschte Vergleich mit einer Geraden (Verlauf der Verteilungsfunktion einer Normalverteilung im Wahrscheinlichkeitspapier bzw. im NormProbPlot) wird dadurch nicht beeinträchtigt.Wegen der Nichteindeutigkeit der Quantil-Bestimmung für nicht streng monotone (empirische) Verteilungsfunktionen (rechtsseitig stetige Treppenfunktionen) stehen die Darstellungen im Wahrscheinlichkeitspapier und im NormProbPlot nicht im Widerspruch zueinander !
Der k-te Wert x*k in der Variationsreihe ist nämlich gleichzeitig Quantil der empirischen Verteilungsfunktion sowohl zum Niveau k / n als auch zum Niveau ( 2k - 1 ) / 2n und nicht zuletzt auch zum Niveau k / ( n + 1 ) oder ( k - 1 ) / n usw.
Zur Erinnerung die Quantil-Definition:
Die Kennzahl xgamma, 0 < gamma < 1, einer Zufallsgröße X heißt Quantil der Ordnung gamma,
wenn die Ungleichung P( X < xgamma ) < gamma < P( X < xgamma ) erfüllt ist.
Damit erfüllt der k-te Wert x*k der Variationsreihe die Quantil-Definition sowohl für das Wahrscheinlichkeitsniveau k / n als auch für das Wahrscheinlichkeitsniveau ( 2k - 1 ) / 2n (und auch für das Wahrscheinlichkeitsniveau k / ( n + 1 ) oder ( k - 1 ) / n, also für jedes Niveau gamma mit ( k - 1 ) / n < gamma < k / n ):
P( X < x*k ) < k / n < P( X < x*k ) und P( X < x*k ) = ( k - 1 ) / n < ( 2k - 1 ) / 2n < P( X < x*k ) = k / n
Damit ist die statistische Grafik vom Typ NPP korrekt, obwohl im Vergleich zum Wahrscheinlichkeitspapier die Punktwolke etwas niedriger liegt.
-
Ludwig Paditz,
15. März 2000