- Im Bedienhandbuch beginnt das Kapitel 7 (STATISTIK/REGRESSIONS-BERECHNUNGEN) auf S.157 mit
dem Satz
"Es ist möglich, Standardabweichungen und Mittelwerte für Statistik im 1-Variablen- oder 2-Variablen-Format zu bestimmen."
Meine Studenten kennen z.B. die Sprechweise "Mittelwerte für Statistik im 1-Variablen-Format" nicht.
Sie ahnen aber, wenn sie Grundbegriffe der statistischen Methodenlehre kennen, daß es hier um den "Mittelwert einer konkreten Stichprobe" geht.
Bei dem "1-Variablen-Format" handelt es sich dann um eine Stichprobe ( x1 , x2 , ... , xn ) vom Stichprobenumfang n
und im "2-Variablen-Format" ist die zweidimensionale Stichprobe ( (x1 , y1) , (x2 , y2) , ... , (xn , yn) ) gemeint (n Datenpaare).
Damit wäre der oben zitierte Satz für den deutschsprachigen Nutzer besser verständlich, wenn er etwa wie folgt lauten würde:
"Es ist möglich, Standardabweichungen und Mittelwerte für konkrete ein- oder zweidimensionale Stichproben zu bestimmen."
- Auf S. 338 des Bedienhandbuches findet man die Beschreibung der TR-Funktion SYSTEM
im TOOL-Menü:
"Einstellung auf die Betriebsart zur Lösung linearer Gleichungen von Polynomen 5. Grades"
Hier verzweifelt der Nutzer vollkommen, denn von der "Lösung linearer Gleichungen von Polynomen" hat er weder in der Schule noch in der Hochschule jemals etwas gehört.
Ein Polynom 5. Grades ist im Unterricht z.B. wie folgt erklärt worden:
p5(x) := a5 * x5 + a4 * x4 + ... + a1 * x1 + a0 oder indexfrei z.B. p5(x) := a * x5 + b * x4 + c * x3 + d * x2 + e * x1 + f
Eine lineare Gleichung mit 5 Unbekannten hat z.B. die Gestalt
a * x + b * y + c * z + d * u + e * v = f
Was ist also wohl im SYSTEM-Untermenü zu erwarten? Es geht, wie man beim Aufruf der TR-Kommandos feststellt, um die Lösung eines inhomogenen linearen Gleichungssystems (LGS) mit einer Koeffizientenmatrix vom Typ (5, 5), d.h. 5 Einzelgleichungen und 5 Unbekannte. Die dafür notwendige Koeffizientenmatrix und der Vektor der Zahlenwerte auf der rechten Seite des Systems werden in eine vorbereitete Tabelle eingegeben, die man über das SYSTEM-Untermenü öffnet:
Aufruf des TOOL-Menüs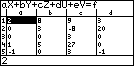
Geöffnete Tabelle zum Eintragen der Koeffizientenmatrix und der rechten Seite des inhomogenen LGS (linker Tabellenteil)
Geöffnete Tabelle zum Eintragen der Koeffizientenmatrix und der rechten Seite des inhomogenen LGS (rechter Tabellenteil)
Endergebnis (nach dem Betätigen der EXE-Taste)
Im TR-Handbuch gibt es keinen Hinweis darauf, daß die Koeffizientenmatrix regulär sein muß, andernfalls erhält man nämlich "ERROR 02":
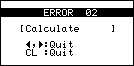
Fehlermeldung bei singulärer Koeffizientenmatrix
Auf S. 270 des Handbuches findet man dann die Erklärung dazu: "Ausführung einer Division durch Null". Damit kann man vermuten, daß der TR mit der Cramerschen Regel rechnet. Hier wird durch die Koeffizientendeterminante dividiert, die bei regulären Koeffizientenmatrizen von Null verschieden ist.
Ein Student, der diesen mathematische Hintergrund kennt, weiß mit der Fehlermeldung etwas anzufangen. Ein Schüler, der mit dem Gaußschen Algorithmus rechnet, wundert sich und versteht die Welt nicht mehr: "Warum bringt der GTR den Fehlerkode 02?" Der Schüler zieht für sich den Schluß: "Mathematik ist schwer erlernbar und erst recht kaum zu begreifen. Auch der komfortable GTR hilft mir hier nicht weiter!"- Zurück zur Statistik:
n ist der Stichprobenumfang der konkreten Stichprobe. Auf S. 158 der Bedienhandbuches wird n als "Stichprobenzahl" erklärt. Unter "Stichprobenanzahl" könnte man mehrere Stichproben vermuten (evtl. mit unterschiedlichen Stichprobenumfängen). Warum wird nicht, wie im Deutschen üblich, der Begriff "Stichprobenumfang" verwendet?
Mit Q1 wird das Quantil einer Stichprobe zum 25%-Niveau, mit Q2 zum 50%-Niveau (auch Median genannt) und mit Q3 zum 75%-Niveau bezeichnet, d.h. mit der empirischen Verteilungsfunktion y = Fn(x) (rechtsseitig stetige Treppenfunktion) gilt
Fn(Qk - 0) < 0,25*k < Fn(Qk + 0) = Fn(Qk) , k = 1, 2, 3.
Im Bedienhandbuch ist "Med" der Median und Q1 der "Median von Med und kleinster Wert" usw.
Warum wird im Bedienhandbuch nicht der hier zutreffende Begriff des Quantils benutzt? Dann wäre vieles schneller verständlich und würde den Lehrinhalten aus dem Unterricht besser entsprechen.- Schließlich auf S. 190 (Kapitel 7, Abschnitt 4 des Bedienhandbuches) der unverständliche Hinweis:
"Der Rechner verfügt über eine Verteilungsfunktion, mit der sich der Verteilungsstatus von Statistiken bestimmen läßt."
Was ist wohl hier gemeint? Der Rechner verfügt doch über mehrere Verteilungsfunktionen? Gemeint ist wohl:
"Der Rechner verfügt über ein Menü mit Wahrscheinlichkeitsverteilungen, insbesondere statistische Prüfverteilungen."
Z. B. errechnet man mit dem cdfnorm-Kommando cdfnorm(a,b,my,sigma) folgende Intervallwahrscheinlichkeit einer N( my, sigma2 )-Verteilung:
Auf S. 191 des Handbuches wird cdfnorm wie folgt erklärt: cdfnorm( unterer Wert, oberer Wert, Mittel, Standardabweichung )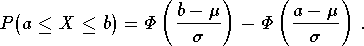
Auf S. 299 des Handbuches steht jedoch: cdfnorm( unterer Wert, oberer Wert, Mittel, Varianz )
Wie soll der Student nun erkennen, ob der letzte Parameter die Standardabweichung oder die Varianz sein muß? Er kann ja beide Varianten vor der Prüfung ausprobieren, sofern er vorher Ungereimtheiten erkennt. Damit trägt der Student in der Prüfung das Risiko, sich vom Bedienhandbuch zum falschen Lösungsweg geleiten zu lassen!
Verbal wird die oben betrachtete Intervallwahrscheinlichkeit auf S. 191 des Handbuches wie folgt erklärt:
"Berechnung der Normalverteilungswahrscheinlichkeit eines definierten Bereiches x bei einer Normalverteilung N( my, sigma2 )"
Mit dem "definierten Bereich x" ist also ein Intervall x = [a, b] gemeint?!
Die Umkehrfunktion der N( my, sigma2 )-Verteilung wird an anderer Stelle (auf S. 167) als "Reziprokwert" bezeichnet. Der Begriff "Reziprokwert" gehört doch eigentlich in die elementare Bruchrechnung?
5. Ein echtes Praxisbeispiel mit dem EL-9600
Die Statistik-Ausbildung der IBS-Studenten beinhaltete u.a. den Chi-Quadrat-Unabhängigkeitstest in Kontingenztafeln. Diese Aufgabe kann der EL-9600 unkompliziert lösen.
Wir betrachten dazu ein mit der Computer-Software SPSS ausgewertetes Beispiel aus dem Buch [3], S. 118.
0,736
Y = 1
Y = 2
Y = 3
X = 1
35
36
34
X = 0
221
207
175
In der Tabelle wurden n = 708 mittelständische Unternehmen wie folgt erfaßt:
Die Zufallsgröße X kodiert den "Förderträger":
X = 1 bedeutet: EU-Fördermittel erhalten
X = 0 bedeutet: keine EU-Fördermittel erhalten
Die Zufallsgröße Y beschreibt die "Umsatzgrößenklasse" in Mio. DM p.a.:
Y = 1 bedeutet: Umsatz < 5
Y = 2 bedeutet: 5 < Umsatz < 20
Y = 3 bedeutet: Umsatz > 20
Die in der Kontingenztafel enthaltenen absoluten Häufigkeiten ( Hi j )i = 1, 2; j = 1, 2, 3 geben die empirisch erfaßte Aufteilung der n befragten Unternehmen wieder.
Die Tabelle 21 in [3], S. 118, enthält darüber hinaus die statistische Kennzahl 0,736. Im zitierten Buch ist diese Kennzahl nicht erläutert. Jedoch wird dann daraus eine (unkorrekte) Schlußfolgerung gezogen, nämlich daß die umsatzstärksten Unternehmen eher Fördermittel erhielten als umsatzkleinere Unternehmen.
Mit dem EL-9600 kann man zunächst die statistische Kennzahl 0,736 recht einfach überprüfen. Es wird dazu der Chi-Quadrat-Test (Bedienhandbuch S. 179) benutzt. Leider gibt das Bedienhandbuch keine genaue Auskunft darüber, um welchen Chi-Quadrat-Test es sich denn genau handelt (Chi-Quadrat-Unabhängigkeitstest oder Chi-Quadrat-Homogenitätstest oder Chi-Quadrat-Anpassungstest oder Chi-Quadrat-Streuungstest usw.)
Es handelt sich hier sowohl um den Chi-Quadrat-Unabhängigkeitstest als auch um den Chi-Quadrat-Homogenitätstest, da beide Testverfahren mit den gleichen Testgrößen arbeiten - lediglich die Nullhypothesen sind unterschiedlich definiert (vgl. auch [1], Kapitel 21.5, S. 285ff):

Chi-Quadrat-Test im EL-9600 (STAT-Menü)
Zuerst muß die Kontingenztafel als Matrix mat A abgespeichert werden:

Aufruf des Matrixeditors (MATRIX-Menü)
Eintragung der Kontingenztafel im Matrixeditor
Die zum Fall der stochastischen Unabhängigkeit der Zufallsgrößen X und Y gehörenden Häufigkeiten ( Hi . * H. j / n ) i = 1, 2; j = 1, 2, 3 sollen nach der Rechnung in mat B abgespeichert werden. Im Bedienhandbuch (S. 179) wird dies irreführend als "Testresultat" bezeichnet. Weiter unten erkennt man, daß das eigentliche Testresultat in der kritischen Irrtumswahrscheinlichkeit p besteht, da hieraus im direkten Vergleich mit der vorzugebenden Irrtumswahrscheinlichkeit alpha sofort die korrekte Testentscheidung getroffen werden kann. mat B hat damit keinerlei Bedeutung für die zu treffende Testentscheidung!
mat A und mat B sind vom gleichen Typ (r, s) mit r = 2 und s = 3.
Im STAT-Menü findet man also das Untermenü TEST und dort das Eingabefenster für den Chi-Quadrat-Unabhängigkeitstest:

Eintragung der Matrixbezeichnungen mat A und mat B
Als "Observed Matrix" wurde die Kontingenztafel mat A eingetragen. Als "Expected Matrix" wurde mat B vorgesehen.
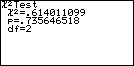
Ergebnisfenster nach Betätigen der EXE-Taste
Das Ergebnisfenster enthält drei Zahlenangaben, die im Bedienhandbuch wieder nicht erklärt sind:
- die PEARSONsche Chi-Quadrat-Statistik zur Kontingenztafel (Wert der Testgröße für den durchgeführten Test) Chi-Quadrat = 0,61401
- die kritische Irrtumswahrscheinlichkeit p = 0,73565
- und die Zahl der Freiheitsgrade der soeben benutzten statistischen Prüfverteilung df = (r - 1) * (s - 1) = 2
(vgl. auch [1], Kapitel 21.5, S. 285ff)
Man erkennt:
Würde man den oben erwähnten Chi-Quadrat-Unabhängigkeitstest mit der Nullhypothese H0: "X und Y sind stochastisch unabhängig" und mit der Irrtumswahrscheinlichkeit (Signifikanzniveau) alpha = 0,05 anhand der empirisch ermittelten Kontingenztafel mat A vom Typ (2, 3) durchführen, hätte die errechnete Testgröße den sehr kleinen Zahlenwert Chi2 = 0,61401, der auf der x-Achse sehr weit links vom Quantil Chi2df, 1-alpha = 5,99 liegt.
Damit liegt die Testgröße außerhalb des kritischen Bereiches, wie es die folgenden Bilder veranschaulichen (Das Koordinatensystem wurde dabei in WINDOW (Rect) wie folgt eingerichtet: Xmin = 0; Xmax = 8; Xscl = 1; Ymin = -0,2; Ymax = 0,7; Yscl = 0,1. ):

kritische Irrtumswahrscheinlichkeit p = 0,73565 (schraffierter Bereich)
Die Testgröße ist die Realisierung einer Zufallszahl mit einer Chi2df - Verteilung (näherungsweise, sogen. statistische Prüfverteilung). Rechts von diesem Testwert Chi2 = 0,61401 liegt nun unter der Chi2df - Dichtefunktion die "Restwahrscheinlichkeit", auch Überschreitungswahrscheinlichkeit, p = P( Chi2 > 0,61401 ) = 0,73565.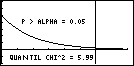
Lage des tatsächlichen kritischen Bereiches (rechts der vertikalen Linie)
Für praktische Rechnungen ist es somit ausreichend, die kritische Irrtumswahrscheinlichkeit p = 0,73565 mit der vorgegebenen Irrtumswahrscheinlichkeit alpha = 0,05 zu vergleichen (anstatt die Testgröße Chi2 = 0,61401 mit dem Quantil Chi2df, 1-alpha = 5,99). Damit muß man nicht extra das Quantil Chi2df, 1-alpha aus einer statistischen Quantil-Tabelle ermitteln und kann wegen p > alpha sofort die richtige Testentscheidung treffen:
Die Testgröße liegt offensichtlich sehr weit vom kritischen Bereich entfernt. d.h. aufgrund des durchgeführten Tests besteht kein Grund, die Nullhypothese abzulehnen. Damit ist die in [3] S. 119 getroffene Aussage
"Die Korrelation von Umsatzgrößenklasse und Förderträgern weist wiederum auf einen Größeneffekt hin: mit steigender Umsatzgrößenklasse steigt die Häufigkeit der geförderten Unternehmen."
auf Grundlage der n = 708 befragten Unternehmen gar nicht statistisch abgesichert!
Im Gegenteil läßt der durchgeführte Test eher den Schluß zu:
Auf Grundlage des durchgeführten statistischen Tests gelangt man zu der Erkenntnis, daß unabhängig von der Umsatzgrößenklasse die Unternehmen bei der EU-Förderung berücksichtigt bzw. nicht berücksichtigt wurden.
Dies ist auch erkennbar, wenn man die "Observed Matrix" mat A und die im Fall der Gültigkeit der Nullhypothese errechnete "Expected Matrix" mat B gegenüberstellt:

"Observed Matrix" mat A
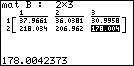
"Expected Matrix" mat B im Fall der stochastischen Unabhängigkeit von X und Y
Man erkennt auch hier: Die Matrizen mat A und mat B unterscheiden sich nicht signifikant, also nicht wesentlich. Das spricht für die Unabhängigkeitshypothese.
Aus Sicht des Chi2-Homogenitätstests bedeutet dies, daß bezüglich der Vergabe von EU-Fördermitteln die Unternehmen einer Umsatzgrößenklasse etwa genauso wie die Unternehmen irgendeiner anderen Umsatzgrößenklasse bedacht wurden. Insofern besteht zwischen den Umsatzgrößenklassen "Homogenität" - oder anders:
In jeder Umsatzgrößenklasse wurden die EU-Fördermittel in etwa gleicher Weise vergeben, also unabhängig von der Umsatzgrößenklasse, der das Unternehmen zuzuordnen ist. Das erkennt man gut bei einem Übergang zu den Spaltenprozenten in der Kontingenztafel (mat C):
Damit kann man vermuten, daß die Autoren in [3] ihre Schlußfolgerungen allein aus den (unwesentlich) steigenden Prozentwerten und nicht aus der Interpretation der angegebenen kritischen Irrtumswahrscheinlichkeit p = 0,736 gezogen haben. Die deterministische Betrachtung von Prozentwerten allein ist allerdings noch kein statistisches Testverfahren.
Die Spalten der Matrix sind annähernd "homogen".
Unterschiede sind aus statistischer Sicht nicht signifikant, also unwesentlich.
Dies gilt auch für die erkennbare leicht steigende Tendenz in Zeile 1 von mat C.
Bemerkung: Würde man die Zeilenprozente betrachten, käme man zu dem gleichen Schluß:

Die Zeilen der Matrix sind annähernd "homogen".
( Jede Zeile variiert unwesentlich um eine Gleichverteilung ( 33,3333; 33,3333; 33,3333 ). )
Aufgabe:
Man überprüfe mit dem EL-9600 die stochastische Unabhängigkeit der Zufallsgrößen X und Y anhand folgender Kontingenztafel und interpretiere das Ergebnis auf einem Signifikanzniveau von alpha = 0,01 oder alpha = 0,10:
0,042
Y = 1
Y = 2
Y = 3
Y = 4
X = 1
5
53
30
10
X = 0
65
347
135
36
Das Datenmaterial in der Kontingenztafel wurde wieder aus [3], S. 113 (Tab. 16) entnommen, einschließlich der nicht nachvollziehbaren Kennzahl 0,042.
X und Y kodieren hier die Antwort des befragten Unternehmens hinsichtlich EU-Förderung (s. oben) und Betriebsgrößenklasse (Beschäftigtenanzahl) mit folgender Bedeutung:
Y = 1 bedeutet: Betriebsgröße < 10
Y = 2 bedeutet: 10 < Betriebsgröße < 50
Y = 3 bedeutet: 50 < Betriebsgröße < 200
Y = 4 bedeutet: 200 < Betriebsgröße < 1000
Lösungshinweis:
Kontingenztafel (transponiert)

Ergebnisbild mit p = 0,062
6. Schlußfolgerungen und Ausblick
Moderne Unterrichtsgestaltung bedeutet neben der Vermittlung von Lehrinhalten auch die Einbeziehung zeitgemäßer Hilfsmittel. Meine Schulzeit verlief noch mit dem "Rechenschieber" und mit Tafelwerken, in denen die sin-, ln- und andere Funktionen tabelliert waren.
Heute sind derartige Tabellen in den Formelsammlungen verschwunden, da Taschenrechner schneller und genauer Tabellenwerte wiedergeben können. In wenigen Jahren wird man auch Werte aus Quantil-Tabellen statistischer Prüfverteilungen vorrangig vom Statistik-Taschenrechner (z.B. TI-83 [8], CFX-9970G [9] oder EL-9600 [7] ) abrufen und nicht mehr interpolieren oder Stammfunktionen aus Integraltafeln vorrangig vom Symbol-GTR (z.B. TI-89 oder ALGEBRA fx 2.0 von CASIO ) abrufen und z.B. keine Partialbruchzerlegung (PBZ) mehr von Hand durchführen.
Damit wird sich der Aufbau von Printmedien weiter verändern. Die Bedeutung von Bedienhandbüchern wird zunehmen, um die hervorragenden GTR im Unterrichtsgeschehen schnell und ohne aufwendiges Suchen im Bedienhandbuch nutzen zu können.
An dieser Stelle sei auf ein weiteres anschauliches Schulbeispiel hingewiesen: Mit der statistischen Datensimulation der Zufallsaussaat einer Blumenwiese, s. auch [5, 6, 10 - 13], wurde der Versuch unternommen, Statistik im Klassenzimmer auf dem Grafik-Display des EL-9600 erlebbar zu machen. Die simulierten Datenpunkte (zweidimensionale Stichprobe mit dem Stichprobenumfang T = 400 z.B.) werden anschließend einem von 80 markierten Rasterfeldern zugeordnet. Im Mittel erhält jedes Rasterfeld Q = 5 "Blumen". Die in den Rasterfeldern zu erwartenden Häufigkeiten werden im Histogramm dargestellt und mit möglichen theoretischen Wahrscheinlichkeitsverteilungen verglichen, s. auch [2].
Ein anderes instruktives Taschenrechnerexperiment zur Auswertung statistischer Daten besteht in einem Würfelexperiment, vgl. auch [4, 14 - 16], das wiederholt mit dem EL-9600 simuliert wird. Es werden zum einen aus mehrfach ( M = 300 ) simulierten Stichproben (Stichprobenumfang z.B. jeweils N = 100 ) zur Augenzahl eines "idealen" Würfels M neue Zufallszahlen (Chi2-Testgrößen zum Chi2-Anpassungstest) errechnet, um daraus die statistische Prüfverteilung (Chi25 - Verteilung) zu simulieren. Zum anderen wird unter Beibehaltung der Nullhypothese ("idealer" Würfel) ein "gezinkter" Würfel mehrfach simuliert (erneut z.B. mit M = 300 und jeweils N = 100, also wiederum 30000 Augenzahlen mit dem EL-9600 !). Man erkennt im Graphik-Display des Taschenrechners eine deutliche Rechtsverschiebung der ursprünglichen Dichtefunktion der statistischen Prüfverteilung, die eben bekanntermaßen nur eintritt, wenn die Nullhypothese falsch war. Anhand der durchgeführten Simulationen lassen sich im Unterricht die entstehenden Wahrscheinlichkeiten für den Fehler 1. und 2. Art diskutieren.
Das Sharp-Electronics-Unternehmen hat sich zum Ziel gestellt, seine TR-Entwicklungen zukünftig noch stärker auf pädagogisch-didaktische Lernaspekte zu orientieren. Damit soll auch dem leistungsschwachen Schüler oder Studenten ein Hilfsmittel in die Hand gegeben werden, wo Mathefrust zur Mathelust wird.
Natürlich bedeutet dies auch im deutschen Bedienhandbuch, die oben kritisierten Mängel abzustellen. Zum anderen nimmt die Verantwortung der Hochschullehrer (HSL) für die ihnen anvertrauten Studenten zu:
HSL sollten z.B. in der Statistik DIN-gerechte Lehrinhalte vermitteln und dabei in den Studenten Kritikvermögen entwickeln, um den Wirrwarr in Bedienhandbüchern zu durchschauen. Damit kann mit dem EL-9600 nutzbringend gearbeitet werden bis hin zur richtigen verbalen Interpretation der erzielten TR-Ergebnisse.
Literaturhinweise
- [1] Aulenbacher,G., Paditz,L., Wabel-Frenk,U.:
- Lehr- und Übungsbuch Mathematik, Band 3: Lineare Algebra - Stochastik (s. Zbl. f. Math. Nr.: 854.00004)
- (Hrg. v. Prof. Dr .W.Preuß, HTW Dresden(FH),
u. Prof. Dr. G.Wenisch, FH Darmstadt),
Fachbuchverl. Leipzig im Hanser Verl. München 1996 (1.Aufl.), 2001 (2.Aufl.), 356 S., ISBN: 3-446-21682-0. - [2] Paditz,L.:
- "Statistische Blumenwiese" auf dem Graphikrechner (Sharp EL-9600)
- in: abakus (Journal für Mathematiklehrer) Nr. 3 (1999), S. 6. (Hrg. Sharp Electronics (Europe) GmbH Hamburg)
- Internetabruf: http://www.sharp-eu.com/germany/produkte/rechner/formular/Abakus99.PDF
- [3] Pohl,H.-J., Nawroth,G.:
- Das mittelständische Unternehmen unter dem Einfluß privatwirtschaftlicher und wirtschaftspolitischer Ziele
- 1. Aufl., Verlag R. F. Wilfer, Fuchsstadt 1995, 220 S.
Internetadressen
- [4] Edwards,C.C.:
- Does a TI-8x Cast a Fair Die?
- in der elektronischen Zeitschrift: Eightysomething!, Vol. 6 (1997), No.3, p. 9-10.
- (siehe: http://www.comcal.net/www.ti.com/calc/docs/80xthing.htm oder http://www.comcal.net/www.ti.com/calc/docs/act83stat.htm)
- siehe auch: http://www.comcal.net/www.ti.com/calc/docs/act/pdf/s9780so3.pdf oder http://www.blackgold.ab.ca/curric/math/pdf/s9780som.pdf
- [5] MathsNet:
- Growing dandelions on an EL-9600
- http://www.mathsnet.net/graphcal/dandelion_EL9600.html
- [6] MathsNet:
- Growing dandelions on a TI-83
- http://www.mathsnet.net/graphcal/dandelion.html
- [7] Paditz,L.:
- Bestimmung von Quantilen der t-Verteilung mit dem EL-9600
- http://www.informatik.htw-dresden.de/~paditz/tquane96.html
- [8] Paditz,L.:
- Bestimmung von Quantilen der t-Verteilung mit dem TI-83
- http://www.informatik.htw-dresden.de/~paditz/tquant83.html
- [9] Paditz,L.:
- Bestimmung von Quantilen der t-Verteilung mit dem CFX-9850G PLUS (oder CFX-9970G)
- http://www.informatik.htw-dresden.de/~paditz/tquancfx.html
- [10] Paditz,L.:
- Zufallsaussaat einer Blumenwiese mit dem EL-9600
- (Datensimulation - graphische Datenauswertung)
- http://www.informatik.htw-dresden.de/~paditz/padite96.html
- [11] Paditz,L.:
- Zufallsaussaat einer Blumenwiese mit dem TI-83
- (Datensimulation - graphische Datenauswertung)
- http://www.informatik.htw-dresden.de/~paditz/paditt83.html,
- http://www.ti.com/calc/deutschland/pdf/mat/paditz01.pdf
- [12] Paditz,L.:
- Zufallsaussaat einer Blumenwiese mit dem CFX-9850G PLUS
- (Datensimulation - graphische Datenauswertung)
- http://www.informatik.htw-dresden.de/~paditz/paditcfx.html
- [13] Paditz,L.:
- Zufallsaussaat einer Blumenwiese mit dem CFX-9970G
- (Datensimulation - graphische Datenauswertung)
- http://www.informatik.htw-dresden.de/~paditz/paditcfy.html
- [14] Paditz,L.:
- Würfelexperiment mit dem gezinkten Würfel und Chi2-Anpassungstest
- (Untersuchung einer statistischen Prüfverteilung mit dem EL-9600)
- http://www.informatik.htw-dresden.de/~paditz/fairdie2.html
- [15] Paditz,L.:
- Würfelexperiment mit dem gezinkten Würfel und Chi2-Anpassungstest
- (Untersuchung einer statistischen Prüfverteilung mit dem TI-83)
- http://www.informatik.htw-dresden.de/~paditz/fairdti2.html
- [16] Paditz,L.:
- Würfelexperiment mit dem gezinkten Würfel und Chi2-Anpassungstest
- (Untersuchung einer statistischen Prüfverteilung mit dem CFX-9850G Plus oder CFX-9970G)
- http://www.informatik.htw-dresden.de/~paditz/faircfx2.html
- [17] Sharp Electronics (Europe) GmbH Hamburg:
- Lehrer-Info-Service
- http://www.sharp.de/index2.htm?/10/index_schul.asp?mc=9
- Verfasser:
Prof. Dr. rer.nat.habil. Ludwig Paditz,
Hochschule für Technik und Wirtschaft Dresden (FH),
Fachbereich Informatik/Mathematik
letzte Änderung: 20. September 2000,
Abruf dieses Dokuments unter http://www.informatik.htw-dresden.de/~paditz/bed_hb96.html möglich.
(in gedruckter Form in:
Berichte und Informationen (Hochschule für Technik und Wirtschaft Dresden (FH)),
Hrsg.: Der Rektor der HTW Dresden (FH), Bd. 7 (1999), Heft 2, S. 83-90.)
Kontakt per e-mail: paditz@informatik.htw-dresden.de
Internet: http://www.informatik.htw-dresden.de/~paditz/
- Zurück zur Statistik: